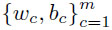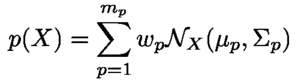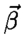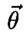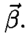|
|
|
|
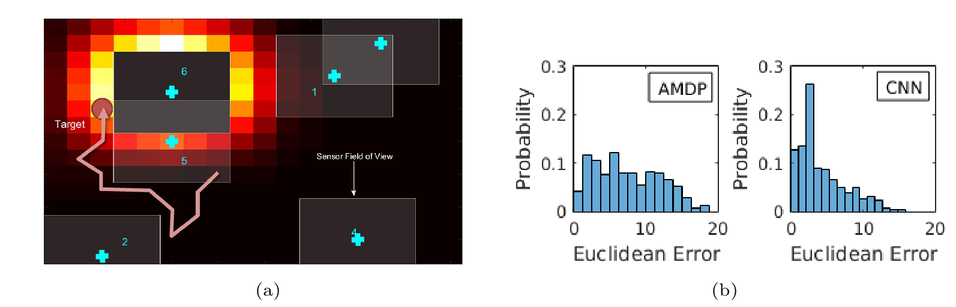
1.INTRODUCTIONFrom self-driving cars1 and storm-chasing aircraft,2 to robots exploring icy Jovian moons3 and patrolling large swaths of open space,4 the future of unmanned autonomous systems looks very promising. Thanks to their ability to gather, process, share, and act on vast amounts of information, autonomous systems are transforming how society thinks about many complex activities that were once considered beyond machine reasoning. Alongside improvements in computing, communication, and sensing hardware, a key technological factor in this development has been the accelerated sophistication of perception, learning and decision making algorithms that can nearly match (or, in some cases, clearly surpass) human reasoning.5 Machines are no longer confined to routine automation tasks focused on low-level control and signal processing - they are being given license to make sense of the larger world and make decisions on their own. However, many hurdles stand in the way of ‘set and forget’ autonomy. Autonomous systems are products of imperfect human engineering, and thus will never operate perfectly out of the box, i.e. knowing everything they will ever need to know to behave exactly as needed. With the widespread adoption of non-deterministic perception, learning, and planning algorithms to cover these gaps, there is still no way yet to guarantee that autonomous systems will behave as intended in all circumstances.6,7 The space exploration domain highlights these challenges: how should an autonomous robot explorer reason about what to do and expect on an icy Jovian moon, if it is gathering detailed data about conditions there for the very first time? Prior knowledge from coarse remote sensing data, human expertise, etc. will be vital to designing the autonomy beforehand, but are not enough to ensure that the robot will be completely self-sufficient. The robot will encounter unexpected situations during the mission that require reasoning beyond its designed capabilities, and which will be impractical to handle via the traditional means of teleoperation or extremely detailed planning from the ground.8 Hence, the old adage ‘no man is an island’ applies to unmanned autonomy as well. Intelligent autonomy should not just be defined by the ability to gather, process, and act on information completely on its own. Rather, it should also include the ability to seek out and exploit other autonomous agents (including humans) for help when needed. This view naturally follows from the under-appreciated fact that ‘autonomy’ represents a relationship, in which a machine is delegated by a user to perform certain tasks.9 As such, it should be kept in mind that an autonomous system (or, any intelligent reasoning machine) represents a deliberate complementary extension of human reasoning – not merely a wholesale replacement of it. Human-machine interaction should therefore be considered an essential component of unmanned autonomy, alongside perception, planning, learning, etc. Autonomy should enable stakeholders and users (soldiers, pilots, scientists, astronauts, farmers, etc.) to stay in/on the loop to delegate, assess and help improve operations, while also keeping them at a safe distance from dull, dirty and dangerous tasks (especially ones they cannot perform well). This in turn raises issues of managing trust for human-machine interaction. If machines and humans are to trust (i.e. willingly depend on) each other, then each must be able to communicate and form useful mental models of the other's abilities, goals, percepts and actions.10 Yet, effective human-machine interaction is difficult to realize in practice, and is often only considered after systems are already designed. Indeed, human-machine interaction is sometimes viewed as a ‘necessary evil’: a post hoc band aid for corner cases where planning and perception haven't caught up yet. Such thinking opens the door to poorly designed human-machine interfaces, which can lead to many unintended (yet avoidable) consequences such as loss of situational awareness, user distrust, system misuse and abuse. 11 This also prematurely shuts out novel pathways to exploiting collaborative human and machine reasoning from the outset. Sophisticated strategies for integrated human-autonomy interaction have begun to develop along these lines. For instance, there is much research nowadays on human-assisted robot planning using multi-modal commands, e.g. natural language speech, sketches or physical gestures.12-16 However, there are also many important implications for reliable sensing, data fusion and perception, which are still major choke points for unmanned systems.17 This work summarizes our recent and ongoing research toward harnessing ‘human sensors’ for autonomous information gathering tasks. The basic idea behind is to allow human end users of autonomous systems (i.e. non-experts in robotics, statistics, machine learning, etc.) to directly ‘talk to’ the information fusion engine and perceptual processes aboard any autonomous agent. Our approach is grounded in rigorous Bayesian modeling and fusion of flexible semantic information derived from user-friendly interfaces, such as natural language chat and locative hand-drawn sketches. This naturally enables ‘plug and play’ human sensing with existing probabilistic planning and perception algorithms; that is, human sensors can freely provide information to autonomy without undermining its ability to reason, or forcing undesirable dependencies on human inputs. We have successfully demonstrated our fusion methods and interfaces with real human-robot teams in target localization applications. Section 2 provides some background for probabilistic modeling and reasoning. Sections 3 and 4, respectively, describe our work on Bayesian fusion of soft data provided via semantic natural language and locative hand drawn sketching for target search. 2.PROBABILISTIC AND BAYESIAN REASONING FOR AUTONOMYPerception and decision making architectures for unmanned autonomous systems can be described in terms of the classical closed-loop ‘observe-orient-decide-act’ (OODA) process.18 The ‘decide’ and ‘act’ portions (planning and control) are typically designed to maximize some set of performance optimality criteria, whereas the ‘observe’ and ‘orient’ portions (sensing and perception) are designed to extract maximum information from environmental signals to support decision making and execution. Modern state space and optimal control theory underscores the importance of accounting for both model and state uncertainties in such closed-loop processes. Such uncertainties directly govern how an agent would best decide to gather more information (acting to observe) and what information it should prioritize gathering (observing for action). Due to their highly flexible nature and ease of use for describing stochastic uncertainties, probabilistic models have been adopted as the lingua franca in modern robotics and autonomy. 19 The development of probabilistic graphical model (PGM) theory in particular provides a powerful unified formal framework for combining these techniques in a scalable way.20 PGMs enable efficient embedding and reasoning over complex probabilistic dependencies, and thus make it trivial to model high-dimensional joint probability distributions. PGMs can also integrate deterministic information and constraints, e.g. based on causal and logical reasoning, and permit hierarchical reasoning on uncertain model structures. With these properties, PGMs make it relatively easy to perform Bayesian inference to update probabilistic knowledge in light of new information. The basic premise of Bayesian inference is simple: given some unknown set of random variables X and some observed data in random variables Y that obey some joint probability distribution P(X, Y), Bayes' rule computes an updated posterior probability distribution P(X|Y) that reflects how much the probability of obtaining any possible value of X is affected by the evidence Y. Large ‘forward models’ for autonomous perception and planning problems can be represented by PGMs that decompose P (X, Y) into an easily obtainable set of prior distribution P(X) and likelihood (or evidence) functions P(Y|X). This decomposition greatly simplifies the operations involved in Bayesian inference to find P(X|Y). Then P(X|Y) (the ‘inverse’ of the joint P(X) and P(Y|X) forward model) can be subsequently analyzed to get a single ‘best’ estimate value X, e.g. as done sequentially in the Kalman filter, or in batch form for maximum a posteriori (MAP) estimates in robotic pose graphs.21 The posterior P(X|Y) can also passed directly to some other reasoning algorithm for decision making and planning, e.g. a policy function for a probabilistic planner. 19 2.1Bayesian Soft-Hard Data FusionProbabilistic models and Bayesian reasoning provide a powerful general framework for augmenting robotic perception systems with ‘human sensors’, which can provide soft data to complement ‘hard data’ from conventional sensors such as lidar, cameras, sonars, etc. in partially observable environments. ‘Soft data’ is any set of observations that originates from human sources. 22 For instance, human pilots and payload specialists in wilderness search and rescue (WiSAR) missions can interpret video feeds and electro-optical/IR data streams provided by small fixed-wing UAVs, and can spot important clues that help narrow down probable lost victim locations and movements. 23 Likewise, in large-scale surveillance for defense applications, dismounted soldiers can provide evidence on the whereabouts and behaviors of potential intruders moving across unsecure areas; it is desirable to directly fuse such soft data with hard data from UAV patrols to improve intruder detection and tracking performance. Combined hard-soft sensing can also help cope with design limitations in UXV systems, where autonomous vehicles are subject to hardware constraints that restrict onboard sensing, processing and communication abilities. Soft data integration also lets humans stay ‘in the loop’ without overloading them with cognitively demanding planning/navigation tasks. 24 A key problem then is: how should soft sensor data be formally integrated with hard data to augment robotic estimation and perception algorithms? Figure 1 shows the corresponding PGM for the generic human-robot sensor fusion problem, where sensor model parameters Θ for both hard and soft sensors may also be unknown, and thus may have to be estimated along with the state of interest X. Soft data can be broadly related to either ‘abstract’ phenomena that cannot be measured by robotic sensors (e.g. labels for object categories and behaviors) or measurable dynamical physical states that must be monitored constantly (object position, velocity, attitude, temperature, size, mass, etc.)22 Our work focuses on the latter, under the key assumption that humans are not oracles: as with any other sensor data, human observations are subject to errors, limitations and ambiguities that must be modeled properly. We aim to adapt widely used statistical sensor fusion and robotic state estimation algorithms, e.g. Bayes filters and the like, so that soft data can be exploited with minimal effort on the part of the robot or the human sensor. 3.BAYESIAN FUSION OF SOFT LANGUAGE OBSERVATIONSRefs. 25-27 were among the first to develop Bayesian fusion techniques allowing human sensors to directly ‘plug into’ robotic state estimation and perception algorithms. However, these works assume that humans report data the same way robots do, and thus greatly limit the flexibility of human-robot communication. In the context of target tracking with extended Kalman filters, for instance, ref. 25 assumes that humans provide numerical range and bearing measurement reports (‘The target is at range 10 m, bearing 45 degrees’). Ref. 28 showed how to model and fuse flexible semantic natural language soft data to provide a broad range of positive/negative information for Bayesian state estimation, e.g. ‘The target is parked near the tree in front of you’, ‘Nothing is next to the truck heading North’. One nice theoretical property of the resulting fusion algorithm is its ability to directly plug into Gaussian mixture (GM) filters for state estimation. GM filters can accurately represent complex posterior pdfs, while avoiding the curse of dimensionality encountered by grid or particle filter methods.25,29,30 We briefly summarize the cooperative human-robot state estimation method developed in ref. 28 and discuss several recent extensions to address the issues of semantic likelihood sensor modeling, natural language processing, and optimal querying for active semantic sensing. 3.1Bayesian Fusion of Semantic DataLet X be a continuous random vector representing the dynamic state of interest (e.g. target location, velocity, heading) with prior pdf p(X) (which may already be conditioned on hard data), and D be a discrete random variable representing a human-generated semantic observation related to X (e.g. ‘The target is on the bridge', ‘The target is heading over the bridge and slowing down’, etc.). Given the likelihood function P(D|X), Bayes' rule gives the posterior pdf where P(D|X) models the human's ‘semantic classification error’ as a function of X. If D = l corresponds to one of m exclusive semantic categories for a known dictionary, then a softmax function can be used to model P (D = l|X), Fig. 2 (a) shows an example softmax model for semantic spatial range and bearing observations in 2D. An important feature of this likelihood model is that, for a given parameter set of class weights and biases Θ = Figure 2.(a) Probability surfaces for example softmax likelihood model, where class labels take on a discrete range in ‘Next To’,‘Nearby’,‘Far From’ and a canonical bearing ‘N’,‘NE’,‘E’,‘SE’,…,‘NW’; (b) MMS model for semantic range derived from softmax model in (a), using 1 subclass for ‘next to’, 8 subclasses for ‘nearby’ and 8 subclasses for ‘far’; (c)-(d) ‘Nearby’ label probabilities in estimated MMS range-only models for two different human sensors. 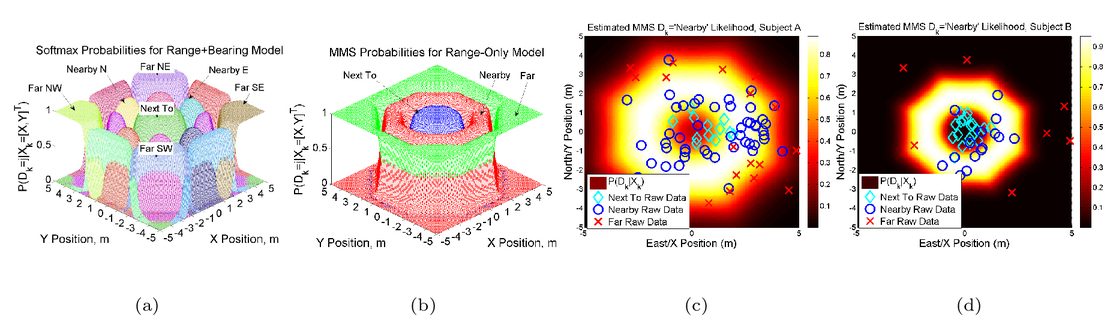 To perform recursive Bayesian data fusion with softmax or MMS likelihoods, eq. (1) must be approximated, since the exact posterior pdf p(X|D) cannot be obtained in closed-form for any prior p(X). Ref. 28 showed that, if P(D = i|X) is generally given by an MMS model with q subclasses for observation label i and the prior is given by a finite Gaussian mixture (GM) with mp prior components, (where wp, μρ ∈ ℝn, and Σρ ∈ ℝn×n are the weights, mean vector and covariance matrix for mixand p), then p(X|D = i) can be well-approximated by a qimp component GM, The weights, means and covariances of posterior component q can be determined by fast numerical quadrature techniques such as likelihood weighted importance sampling (LWIS) or variational Bayesian importance sampling (VBIS).28 These techniques exploit the fact that the exact product of an MMS likelihood function and GM prior is a mixture of non-Gaussian component pdfs, where each component is guaranteed to be unimodal and thus can be well-approximated by a moment-matched Gaussian. To manage the growth of mixture terms from mp to qimp, mixture compression methods such as Runnalls' joining algorithm33 can used to find a GM with mf < qimp components that minimizes an information loss with respect to (3). This allows semantic human sensor data to plug seamlessly into existing GM Bayes filters for hard robot sensor data fusion.25’30 Figure 3 illustrates the semantic data fusion process for an indoor target localization application, discussed in refs. 28, 34 and 35. In this example, a ground robot and a remote human supervisor perform a time critical search for static targets (red traffic cones) using a Bayesian search algorithm with GM prior distributions on the target locations. The robot autonomously plans optimal search paths using negative information gathered from an onboard visual detector, which has a very limited range and field of view. The human supervisor can confirm possible target detections (confirming true detections or false alarms), but can also voluntarily provide semantic observations about the environment based on a live (grainy and delayed) video feed. In this application, the human's semantic observations are selected from a pre-defined dictionary, which filled in templated observations of the form ‘[Something/Nothing] is [preposition][reference object]’. Figure 3.Static target localization application from refs. 28,35. The surveillance area consist of mapped obstacles and landmarks, and targets (orange traffice cones) with unknown locations X given by a Gaussian mixture (GM) prior p(X). An autonomous UGV robot performs Bayesian fusion of prior beliefs with detection/no detection reports from a vision sensor and semantic observations provided by a human supervisor' producing updated GM posteriors for X. The updated GMs are then used by autonomous path planning algorithms to navigate towards likely target positions' i.e. the human only provides sensor observations' and never directly commands or steers the robot.  As shown in the bottom right of Fig. 3, soft semantic data fusion leads to a massive injection of information and hence a significant shift in the robot's beliefs about the target locations. This allows the robot to plan and execute more efficient search paths. The soft semantic data fusion process does not require the human to engage in cognitively demanding planning or control activities: the robot simply responds to new human sensor information by updating its beliefs about the target state and executing corresponding optimal search actions. Experiments with 16 different human participants acting as supervisors35 showed that targets well outside the robot's field of view could be localized to sub-meter accuracy, using only semantic data fusion updates provided by the human (which included both positive and positive observations, i.e. ‘Something is in front of the door’ vs. ‘Nothing is in front of the door’). In these experiments, human supervisors were also allowed to view a live heat map representing the robot's beliefs about the target locations. As such, soft data fusion can be particularly useful as a ‘coarse sensing’ input for both priming and correcting robotic perception in complex dynamic settings. For example, many human supervisors were able to use soft data to correctively/preepmtively ‘nudge’ the robot's beliefs whenever its detector encountered false negatives, thus preventing the robot from wandering away from the true target locations. The fusion of negative semantic information (e.g. ‘There is nothing in this room’) also allowed the robot to quickly narrow down search regions, thus saving considerable time and energy. While promising, these initial results were obtained with significant design constraints on the semantic data fusion system and human-machine interface. For instance, a highly restrictive semantic dictionary and set of softmax/MMS likelihoods were used to model human sensor semantics in order to avoid the up front difficulties of natural language processing. This approach also assumes that it is possible to construct the entire dictionary and set of semantics ahead of time, which is prohibitive for many applications (e.g. mapping and tracking targets in unknown environments). Furthermore, a strictly passive data fusion process was used: the human supervisor would only voluntarily provide inputs if he/she deemed them necessary. The following subsections describe recent advances that address these issues. 3.2Semantic Likelihood Synthesis and CompressionSoftmax and MMS likelihood models are theoretically convenient for recursive data fusion via (3), but it is not immediately obvious how to physically interpret or manipulate these sensor models in different settings. Refs. 36 and 37 established several key properties of general softmax and MMS model geometry to address this issue, and provide the basis for novel solutions to two related problems: semantic likelihood model synthesis, and batch semantic likelihood compression. Likelihood model synthesis: How should softmax/MMS models be constructed ‘from scratch’ and/or dynamically modified in general state spaces X? For instance, we may wish to model likelihood functions in complex 2D/3D spatial domains and beyond to include velocities, angles, etc. Or we may wish to build likelihood models ‘on the fly’ to exploit spatial semantics for newly perceived objects or environments that are mapped in real time. It is thus practically necessary to translate known geometric constraints in X directly into prior specifications/constraints for Θ. This is especially important for learning with sparse human sensor calibration data, and for adapting Θ online to enforce expected geometric properties of likelihood function polytopes in X space. For instance, meaningful spatial invariances can be enforced at different scales and for different reference geometries, e.g. ‘near the table’ vs. ‘near the house’. In Fig. 2 (a), Θ was obtained via maximum liklihood optimization on manually generated ‘prototypical’ training data, which was tuned to produce the desired polytope geometries via trial and error. This brute force approach is computationally expensive: it requires non-convex optimization, and is not suitable for higher dimensional settings. To solve these problems, we can recall and exploit the important fact that the softmax function (2) describes a set of probabilistic polytopes in X space. In particular, the set of log-odds functions between classes i and j define the linear hyperplane boundaries of their corresponding polytopes at different relative probability levels; for equal probabilities ε, we have Thus, if we are given normal vectors where Fig. 4 shows a simple example of synthesizing a semantic MMS likelihood model that describes the space ‘inside’ and ‘outside’ an arbitrary irregular 2D polygon. This specification of 5 polytope face boundaries for m = 6 softmax subclasses (5 softmax subclasses describe ‘outside’, while one describes ‘inside’) leads to a system of NS(n + 1) = 15 linear equations in m(n + 1) = 18 unknown softmax parameters. Since one set of subclass parameters can always be set the zero vector, assuming wi = 0 and bj = 0 for i =‘inside’, gives 15 unknown softmax parameters in 15 difference equations. Thus, in eq. (5), M = I (the identity matrix), and so Figure 4.(a) Polytope specification; (b) resulting subclass regions; (c) subclass probability surfaces with unit normals nji; (d) desired normals magnifed by 80; (e) non-convex likelihood for ‘outside’. 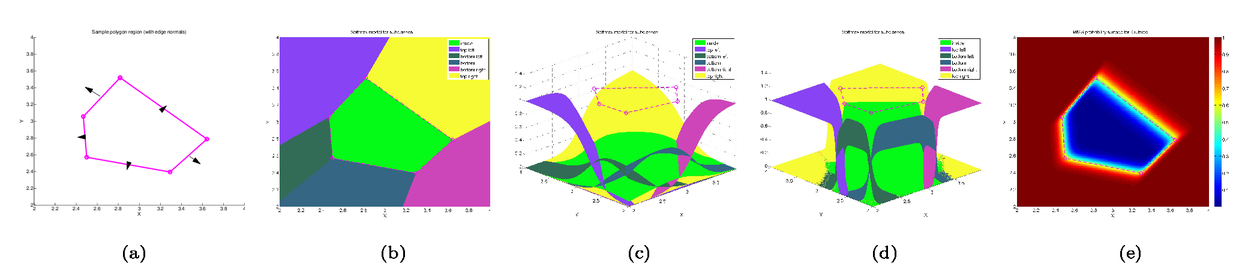 Likelihood model compression: The GM fusion approximation assumes that P(D = i|X) captures all information contained within a semantic human observation D. However, D can contain mixed information about different parts of X, e.g. target position and speed, but not heading. P(D = i|X) could be decomposed into more basic likelihoods that model relevant semantic information after D is parsed (e.g. by a natural language processing front-end, as discussed later). For instance, if Da = i and Db = j correspond to the observations ‘target near building’ and ‘target moving quickly away from building’, then the likelihood for the joint observation D = ([Da = i] Λ [Db = j]) can be modeled as the product of the corresponding softmax/MMS models (assuming both are conditionally independent given X), For No observations Do, o ∈ {1,…, No}, sequential processing via repeated application of the GM fusion and merging approximations could be very expensive and inefficient. Instead, we seek to extend the GM fusion method of28 to handle the general case of ‘batch’ semantic measurement updates for fast online data fusion, where a single ‘compressed’ softmax/MMS likelihood L(D1:No |X) captures all information from the product where I = {i1, i2,…, iNo} is the set of No class observations taken from the No softmax models, where io ∈ {1,…,mo} and mo is the number of classes for the oth softmax model. Assuming that the class labels are ordered within each softmax model, the product model parameters are defined as Eq. (7) is computationally expensive to compute for online fusion for large No and m. As with GM compression algorithms, this motivates approximation of (7) via parameter compression techniques, where m* ≪ m, and the parameters Fig. 5 shows results for compressing a product of three MMS models corresponding to the observation: ‘The target is inside the front yard, near the garage and the front porch’. The likelihoods for the single ‘inside’ and two ‘near’ observations are shifted/scaled from a base MMS model describing the ‘inside’ and ‘outside’ of the gray rectangular region in the upper left of Fig. 5. These results show a great speedup in computation for geometric compression (0.3 secs) over either the exact product or neighborhood fusion method (20 mins and 10 mins for GM fusion, respectively), for a fairly small and acceptable sacrifice in fusion accuracy. 3.3Natural Language Chat InterfacesA human could report soft data by composing structured observations from a list of available statements, as shown upper left in Fig. 6. This ‘direct selection’ interface bypasses the difficulties of natural language processing (NLP), but leads to several major limitations. Firstly, it restricts the human to a rigid pre-defined dictionary and message structure, which may not provide an intuitive or sufficiently rich set of semantics to convey desired information. Secondly, it is very inconvenient to select items one-by-one from a list for structured messaging; especially as the dictionary size m grows, this quickly becomes infeasible and time-consuming enough to render data irrelevant in dynamic settings. Furthermore, this approach does not scale well with environment/problem complexity and lexical richness for soft data reporting. In particular, it is often desirable to provide observations that activate multiple semantic D terms, e.g. ‘Roy is by the table, heading slowly to the kitchen’ simultaneously provides location, orientation and velocity information. Figure 6.Soft data fusion PGMs for direct selection and natural language chat interfaces in target localization application.  We are developing an unstructured natural language chat interface to support fast and highly flexible ‘free-form’ soft data reporting. The chat interface should ideally support a wide range of semantics. However, it is highly non-trivial to deriving meaningful and contextually relevant dynamic state information from free-form chat observations O. Unlike structured messages, it is infeasible to explicitly construct likelihood functions p(O|X) in advance to find the Bayes posterior p(X|O). Many different chat messages can also convey similar kinds of information, leading to additional uncertainties in lexical meaning (i.e. possible translation errors) in addition to intrinsic semantic (state spatial meaning) uncertainty. For example, the phrases ‘That guy's moving past the books’, ‘Roy next to the bookcase going to kitchen’, and ‘He's nearby shelf heading left’ all overlap in the sense that they could all to essentially refer to a structured set of atomic phrases: ‘Target is near the bookcase; and Target is moving toward the kitchen’. Our approach to handle free-form chat inputs separately accounts for lexical/translation uncertainties (using off-the-shelf NLP components, e.g. probabilistic syntactic parsers and sense-matchers) and semantic/meaning uncertainties (via state filtering) in a statistically consistent way that avoids joint reasoning over a large set of latent variables. The main idea is to translate a given Ok at time k into a reasonable ‘on the fly’ estimate of the likelihood p(Ok|Xk) via a very large (possibly expandable) dictionary of latent (where Ok is conditionally independent of Xk given Ref. 38 details one approach for estimating Figure 7 shows initial proof-of-concept results, using arg maxDk s(Dk, Tk) to select template sensor statements that are most similar to the input tokenization for four correctly tokenized test phrases. In this example, 2682 possible template statements are considered, which covers 79.81% of the 208 input sentences collected in a pilot experiment with 12 human participants. From left-to-right, the four columns demonstrate the effects of increasing dissimilarity with template statements: the first input sentence is exactly a sensor statement template; the second input sentences replaces a spatial relation template token, ‘near’, with a non-template token, ‘next to’; the third input sentence replaces the grounding and changes the positivity; and the fourth is an imprecise reformulation of the first sentence. The results are promising, as the top-scoring statements are all qualitatively similar to the original phrase and produce sensible fusion results. 3.4Optimal Value of Information Querying for Active Soft Data FusionWe have thus far only considered passive data fusion strategies, where human sensors voluntarily provide observations as they see fit. However, semantic data fusion can also be extended to incorporate active soft sensing, i.e. intelligent ‘closed-loop’ querying of human sensors to gather information that would be most beneficial for complex machine planning and perception tasks. Active sensing problems have a rich tradition in target tracking and controls communities, but have focused on hard data sources such as radar, lidar, cameras, etc. One particularly relevant issue is the sensor scheduling problem, which seeks optimal selection of sensing assets given constraints on how many can be tasked to deliver quality data at any given instant. This problem also applies to scheduling of interactions between human sensors and autonomous agents: what is the most valuable soft information to request from humans, and when/how should such soft information be obtained? These issues can be tackled within formal planning frameworks that seek to maximize the value of information (VOI) under uncertainty.27 Considering the target localization problem, suppose where E [f](v) is the expected value of f over v. Assuming cost c( This means that soft data To address this, ref. 42 describes a novel querying policy approximation based on deep learning. This approach produces a multi-layer convolutional neural net (CNN) classification model to select among the ns possible semantic queries Figure 8 shows an application of the CNN query policy approximation approach to a dynamic version of the target localization problem. The target moves with random walk dynamics in a 2D grid world, which is incompletely covered by 6 static cameras that can be accessed serially by a human supervisor. In this case, ns = 6, and the problem here is to determine which camera j the human should look through at each time k for the best binary measurement (‘detection’ or ‘no detection’, with known false alarm and missed detection rates). The right plots show the resulting localization errors based on maximum a posteriori (MAP) estimates of the target location obtained from the post-fusion Bayesian posteriors p(Xk|D1:k) at each time. The first histogram shows results using an alternative baseline sensor querying policy based on a partially observable Markov decision process (POMDP) model,43 solved using the feature-based infinite horizon augmented MDP (AMDP) approximation. 19 The results here show that, despite the highly limited coverage area of the cameras, the CNN VOI approximation does a much better job of using querying sensors than AMDP, since it leads to much better tracking of the true target location. However, the CNN policy clearly rests on having adequate training data and an accurate model of the search environment; it is more brittle than the AMDP policy approximation to changes in camera layout or subtle changes in target dynamics (both of which are easily encoded as explicit POMDP parameter variations). A promising research direction to overcome such issues is to combine the strengths of AMDP and CNN policy approximations in a structured manner. To overcome the curse of dimensionality, we are also developing GM adaptations of these policy approximations. 44 4.FUSION OF FREE-FORM LOCATIVE SKETCH DATANatural language data fusion can be easily implemented with predictable verbal communication patterns (e.g. for human operators in specialized operational settings such as soldiers, pilots, WiSAR incident commanders, first responders, etc.) and also tends to work well in structured environments for autonomous perception. However, it can be difficult to adequately capture the intended meaning of ‘off nominal’ or unexpected verbal human sensor observations. Language-based observations may also be difficult to interpret in large unstructured or featureless environments, e.g. outdoor spaces with many non-distinct features (‘near those rocks’, ‘behind the tree’). Furthermore, the soft data fusion techniques discussed so far assume that human sensor models are perfectly known and obtainable via offline calibration, which can be very time-consuming and is not robust to unanticipated semantic context shifts. A priori calibration is also infeasible for large-scale spatial sensing operations with ad hoc human elements that can opportunistically join or leave a sensing network at any time, e.g. hikers and volunteers who provide sporadic reports during a WiSAR mission. To address these issues in the context of outdoor target search, ref. 45 proposed a novel sketch-based interface and probabilistic model for fusing human-generated positive/negative target location observations. This sketch interface allows in situ human search agents to quickly convey binary observations in different regions of the search space X via free-form encirclements drawn directly on known map M, as shown in Fig. 9. Figure 9.Example search map with ‘inside’ and ‘outside’ region free-form human sketches; (left and right) discretization of sketches on search space grid for X to form binary observation grids Sin and Sout, where filled red/blue cells corresponding to observations are assigned value ‘1’ and empty/unobserved cells are assigned ‘0’. 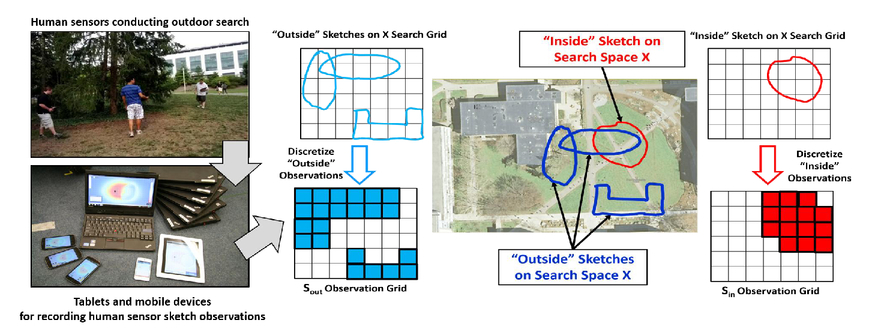 A single human sketch sensor observation in this case specifies ad hoc spatial region boundaries in which the target could either be present/‘inside’ or absent/‘outside’. This protocol enables coarse classification of the search space based on independent positive/negative evidence obtained during the search mission, e.g. from visual terrain sweeps or clues extracted from the search environment (footprints, disturbed features, etc.). For instance, the blue sketches in Fig. 9(b) imply ‘target not in these areas’ (e.g. summarizing negative information obtained by a visual sweep of the areas), while the red sketch region imply ‘target may be around here’ (e.g. which might collectively summarize positive information gathered from clues in the search environment). Such sketch observations are qualitatively similar to ‘belief’ sketches used for priority searches in WiSAR, 46 and are intuitively simple to understand and implement on networked mobile devices (e.g. smartphones, tablets). A key difference is that the sketches here do not directly reflect subjective probabilistic beliefs, but instead indicate possible constraints on the true target state. Such sketch reports must be interpreted very carefully to account for various sources of ‘human sensor noise’. For instance, sketches will not always be drawn precisely (especially in time critical situations) and thus might convey inconsistent observations from the same human at different times (cf. Fig. 9). Tendencies to report positive/‘inside’ or negative/‘outside’ information can also vary significantly across different humans. Given a suitable parametric conditional probability distribution model of a human sensor's sketch observation accuracy, consistent positive/negative information can be extracted from sketch data via Bayesian fusion while accounting for possible observation errors. As such, each sketched ‘inside’/‘outside’ region must be parsed into an uncertain observation vector conditioned on the latent target state X, which is then fused with prior information for X. Ref. 45 describes two key technical contributions to this end: (i) specification of a likelihood function for each human that correctly accounts for spatially correlated information within each sketch; and (ii) a fully Bayesian hierarchical inference procedure for fusing sketch data and estimating target states simultaneously and online in the presence of multiple uncertain human sketch sensor likelihood parameters (which is especially useful if sparse or no training data are available for offline calibration). Figure 10 shows the resulting PGM used for centralized fusion of sketch reports from multiple human sensors in a networked static target localization problem. The human sensor i sketch likelihood parameter variables Θi = (ai, bi, ωi) correspond to true detection rate, false alarm rate, and negative information spatial correlation, respectively. These can be estimated offline with sufficient training data, or estimated online alongside the unknown target state X. The variables labeled Sin and Sout denote parsed grid squares on the map M that take on values of 1 or 0, depending on whether or not human i's ‘inside’/‘outside’ sketch contained those cells. The hyperparameters k control Gamma distribution hyperpriors that are assigned to the set of all human sensor sketch likelihood parameters. The hyperpriors effectively capture ‘population statistics’ for different human sensors, i.e. reflecting the idea that all human sensors tend to have similar values for Θi. This acts as a ‘soft constraint’, which allows information obtained during inference about human sensor i's parameters to indirectly restrict the values that human j's parameters can take on via conditional independence (in particular: if j's sketches are very similar to i's, then we can infer that is probably very similar to Θi). As discussed in ref. 45, simultaneous parameter inference on each set of Θi and data fusion to estimate X can be carried out via a computationally efficient Gibbs Monte Carlo sampler. The Gibbs sampler in this case uses adaptive rejection techniques to draw samples of each unknown variable according to local posteriors that can be easily obtained analytically (up to an unknown normalizing constant) from the PGM itself. Figure 10.PGM for hierarchical Bayesian human sketch sensor data fusion: arrows denote conditional dependencies; shaded nodes denote unknown variables, unshaded nodes denote observations; continuous/discrete random variables indicated by round/square nodes. Cj and Cm denote number of marked cells in the jth ‘inside’ and mth ‘outside’ sketches for human i, respectively (Ni,in and Ni, out are total number of ‘inside’ and ‘’outside’ sketches for human sensor i). Boxes around nodes denote repeated graph substructures.  Figure 11 (a)-(b) shows typical sketch inputs provided by 2 of 6 mobile human sensors performing an outdoor static target localization experiment (locating a small key chain buried somewhere on a campus quad, with a uniform prior p(X) for the target location X). On the other hand, Fig. 11 (c) shows that a sensible target location posterior is obtained using the proposed simultaneous Bayesian parameter and state estimation approach based on the hierarchial PGM in Fig. 10. Fig. 11 (d) shows the resulting posterior false alarm rates obtained for each human sensor using all the corresponding sketch observations shown in Fig. 11 (c). Human sensors who report many false positive ‘inside‘ sketches are estimated to have high false alarm rates bi (e.g. agents 4 and 6), whereas humans who report more negative information via ‘outside’ sketches are estimated to be more reliable (e.g. sensors 1 and 5). The Bayesian inference process automatically accounts for these estimated discrepencies in human sensor quality, and fuses sketch information to update the posterior over X accordingly. This makes the proposed sketch fusion method especially useful for applications like WiSAR, where false alarm and missed detection rates are hard to obtain for human sensors. Figure 11.(a)-(b) Typical sketch inputs provided by 2 different mobile human sensors for a static target search mission (true target location shown as asterisk *); (c) Bayes posterior for X using hierarchical inference on PGM from Fig. 10; (d) posterior estimates for human sensor false alarm parameters bi.  5.CONCLUSIONSProbabilistic models and Bayesian algorithms are firmly established cornerstones for tackling challenging autonomous robotic perception, learning and decision-making problems. Since the next frontier of autonomy demands the ability to gather information across stretches of time and space that are beyond the reach of a single autonomous agent, the next generation of Bayesian algorithms must capitalize on opportunities to draw upon the sensing and perception abilities of humans-in/on-the-loop. This work summarized our recent and ongoing research toward harnessing ‘human sensors’ for general information gathering tasks. The approach described here is grounded in rigorous Bayesian modeling and fusion of flexible semantic information derived from user-friendly interfaces, such as natural language chat and locative hand-drawn sketches. This allows human users (i.e. non-experts in robotics, statistics, machine learning, etc.) to directly ‘talk to’ the information fusion engine and perceptual processes aboard any autonomous agent, while also providing an formal framework for online adaptive human sensor modeling and optimal human sensor querying. This naturally enables ‘plug and play’ human sensing with existing probabilistic algorithms for planning and perception, which we have successfully demonstrated with real human-robot teams in target localization applications. REFERENCESMiller, I., Campbell, M., Huttenlocher, D., Kline, F.-R., Nathan, A., Lupashin, S., Catlin, J., Schimpf, B., Moran, P., Zych, N.,,
“Team cornell’s skynet: Robust perception and planning in an urban environment,”
Journal of Field Robotics, 25
(8), 493
–527
(2008). https://doi.org/10.1002/rob.v25:8 Google Scholar
Argrow, B., Frew, E., Elston, J., Stachura, M., Roadman, J., Houston, A., and Lahowetz, J.,
“The tempest uas: The vortex2 supercell thunderstorm penetrator,”
InfotechAerospace, American Institute of Aeronautics and Astronautics (AIAA),
(2011). Google Scholar
Werner, D.,
“Ambition: Europa,”
Aerospace America Magazine June, 22
–28
(2016). Google Scholar
Kingston, D.,
“Intruder Tracking Using UAV Teams and Ground Sensor Networks,”
in in [German Aviation and Aerospace Conference 2012 (DLRK 2012)],
(2012). Google Scholar
Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., Van Den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M.,,
“Mastering the game of go with deep neural networks and tree search,”
Nature, 529
(7587), 484
–489
(2016). https://doi.org/10.1038/nature16961 Google Scholar
Sweet, N., Ahmed, N., Kuter, U., and Miller, C.,
“Towards self-confidence in autonomous systems,”
in [AIAA InfoTechAtAerospace 2016],
(2016). Google Scholar
Aitken, M., Ahmed, N., Lawrence, D., Argrow, B., and Frew, E.,
“Assurances and machine self-confidence for enhanced trust in autonomous systems,”
in [RSS 2016 Workshop on Social Trust in Autonomous Systems],
(2016). Google Scholar
McGuire, S., Furlong, P., Heckman, C., Julier, S., Szafir, D., and Ahmed, N.,
“Teamwork across the stars: Machine learning to overcome the brittleness of autonomy,”
in [IROS 2016 Workshop on Human-Robot Collaboration: Towards Co-Adaptive Learning Through Semi-Autonomy and Shared Control],
(2016). Google Scholar
Miller, C., Goldman, R., Funk, H., Wu, P., and Pate, B.,
“A playbook approach to variable autonomy control: Application for control of multiple, heterogeneous unmanned air vehicles,”
in in [Proceedings of FORUM 60, the Annual Meeting of the American Helicopter Society],
7
–10
(2004). Google Scholar
Lee, J. D. and See, K. A.,
“Trust in automation: Designing for appropriate reliance,”
Human Factors: The Journal of the Human Factors and Ergonomics Society, 46
(1), 50
–80
(2004). https://doi.org/10.1518/hfes.46.1.50.30392 Google Scholar
Sheridan, T., [Humans and Automation: System Design and Research Issues], Wiley, Santa Monica, CA
(2002). Google Scholar
Tellex, S., Kollar, T., Dickerson, S., Walter, M. R., Banerjee, A. G., Teller, S., and Roy, N.,
“Approaching the symbol grounding problem with probabilistic graphical models,”
in in [AAAI Conference on Artificial Intelligence],
(2011). https://doi.org/10.1609/aimag.v32i4.2384 Google Scholar
Shah, D. and Campbell, M.,
“A robust qualitative path planner for mobile robot navigation using human-provided maps,”
in in [2011 Intl.Conf. on Robotics and Automation (ICRA 2011)],
2580
–2585
(2011). Google Scholar
Tellex, S., Thaker, P., Deits, R., Simeonov, D., Kollar, T., and Roy, N.,
“Toward information theoretic human-robot dialog,”
in [Robotics Science and Systems],
(2012). Google Scholar
Arkin, J. and Howard, T. M.,
“Towards learning efficient models for natural language understanding of quantifiable spatial relation-ships,”
in [RSS 2015 Workshop on Model Learning for Human-Robot Communication],,
(2015). Google Scholar
Howard, T. M., Tellex, S., and Roy, N.,
“A natural language planner interface for mobile manipulators,”
in in [Robotics and Automation (ICRA), 2014 IEEE International Conference on],
6652
–6659
(2014). Google Scholar
Daftry, S., Zeng, S., Bagnell, J. A., and Hebert, M.,,
“Introspective perception: Learning to predict failures in vision systems,”
(2016). https://doi.org/10.1109/IROS.2016.7759279 Google Scholar
Boyd, J. R.,
“[Destruction and creation],”
US Army Comand and General Staff College,
(1987). Google Scholar
Thrun, S., Burgard, W., and Fox, D., [Probabilistic Robotics], MIT Press, Cambridge, MA
(2001). Google Scholar
Bishop, C.,
“Pattern Recognition and Machine Learning,”
(2006). Google Scholar
Morrison, J. G., Gavez-Lopez, D., and Sibley, G.,
“Scalable multirobot localization and mapping with relative maps: Introducing moarslam,”
IEEE Control Systems, 36 75
–85
(2016). https://doi.org/10.1109/MCS.2015.2512032 Google Scholar
Hall, D. L. and Jordan, J. M.,
“[Human-centered Information Fusion],”
Artech House,
(2010). Google Scholar
Goodrich, M. A., Morse, B. S., Engh, C., Cooper, J. L., and Adams, J. A.,
“Towards using Unmanned Aerial Vehicles (UAVs) in Wilderness Search and Rescue,”
Interaction Studies, 10
(3), 453
–478
(2009). https://doi.org/10.1075/is Google Scholar
Lewis, M., Wang, H., Velgapudi, P., Scerri, P., and Sycara, K.,
“Using humans as sensors in robotic search,”
in in [12th International Conference on Information Fusion (FUSION 2009)],
1249
–1256
(2009). Google Scholar
Kaupp, T., Douillard, B., Ramos, F., Makarenko, A., and Upcroft, B.,
“Shared Environment Representation for a Human-Robot Team Performing Information Fusion,”
Journal of Field Robotics, 24
(11), 911
–942
(2007). https://doi.org/10.1002/(ISSN)1556-4967 Google Scholar
Bourgault, F., Chokshi, A., Wang, J., Shah, D., Schoenberg, J., Iyer, R., Cedano, F., and Campbell, M.,
“Scalable Bayesian human-robot cooperation in mobile sensor networks,”
in in [International Conference on Intelligent Robots and Systems],
2342
–2349
(2008). Google Scholar
Kaupp, T., Makarenko, A., and Durrant-Whyte, H.,
“Humanrobot communication for collaborative decision making A probabilistic approach,”
Robotics and Autonomous Systems, 58 444
–456 https://doi.org/10.1016/j.robot.2010.02.003 Google Scholar
Ahmed, N., Sample, E., and Campbell, M.,
“Bayesian multi-categorical soft data fusion for human-robot collaboration,”
IEEE Transactions on Robotics, 29
(1), 189
–206
(2013). https://doi.org/10.1109/TRO.2012.2214556 Google Scholar
Alspach, D. and Sorenson, H. W.,
“Nonlinear Bayesian Estimation Using Gaussian Sum Approximations,”
IEEE Transactions on Automatic Control AC, 17
(4), 439
–448
(1972). https://doi.org/10.1109/TAC.1972.1100034 Google Scholar
Schoenberg, J., Campbell, M., and Miller, I.,
“Localization with Multi-modal Vision Measurements in Limited GPS Environments Using Gauss-sum Filters,”
in in [2009 International Conference on Robotics and Automation (ICRA 2009)],
(2009). Google Scholar
Taguchi, S., Suzuki, T., Hayakawa, S., and Inagaki, S.,
“Identification of Probability Weighted Multiple ARX Models and Its Application to Behavior Analysis,”
in in [48th IEEE Conf. on Decision and Control (CDC09)],
3952
–3957
(2009). Google Scholar
Ahmed, N. and Campbell, M.,,
“On estimating simple probabilistic discriminative models with subclasses,”
Expert Systems with Applications, 39 6659
–6664
(2012). https://doi.org/10.1016/j.eswa.2011.12.042 Google Scholar
Runnalls, A. R.,
“Kullback-leibler approach to Gaussian mixture reduction,”
IEEE Transactions on Aerospace and Electronic Systems, 43
(3), 989
–999
(2007). https://doi.org/10.1109/TAES.2007.4383588 Google Scholar
Ponda, S., Ahmed, N., Luders, B., Sample, E., Hoossainy, T., Shah, D., Campbell, M., and How, J.,
“Decentralized information-rich planning and hybrid sensor fusion for uncertainty reduction in human-robot missions,”
in in [2011 AIAA Guidance, Navigation and Control Conf.],
(2011). https://doi.org/10.2514/MGNC11 Google Scholar
Sample, E., Ahmed, N., and Campbell, M.,
“An experimental evaluation of Bayesian soft human sensor fusion in robotic systems,”
in in [2012 AIAA Guidance, Navigation and Control Conf.],,
(2012). https://doi.org/10.2514/MGNC12 Google Scholar
Ahmed, N. and Sweet, N.,
“Softmax Modeling of Piecewise Semantics in Arbitrary State Spaces for Plug and Play Human-Robot Sensor Fusion,”
in [Robotics: Science and Systems],
(2015). Google Scholar
Sweet, N. and Ahmed, N.,
“Structured synthesis and compression of semantic human sensor models for bayesian estimation,”
in in [2016 American Control Conference (ACC)],
5479
–5485
(2016). Google Scholar
Sweet, N. and Ahmed, N.,
“Towards natural language semantic sensing in dynamic spaces,”
in [2016 RSS Workshop on Model Learning for Human-Robot Communication (MLHRC)],
(2016). Google Scholar
Kollar, T., Tellex, S., Roy, D., and Roy, N.,
“Toward understanding natural language directions,”
in in [Proceeding of the 5th ACM/IEEE international conference on Human-robot interaction - HRI ’10], 259, ACM Press,
(2010). Google Scholar
Mikolov, T., Chen, K., Corrado, G., and Dean, J.,
“Distributed Representations of Words and Phrases and their Compositionality,”
in [NIPS], 1
–9
(2013). Google Scholar
Huber, M. F., Bailey, T., Durrant-Whyte, H., and Hanebeck, U. D.,
“On entropy approximation for gaussian mixture random vectors,”
in in [Multisensor Fusion and Integration for Intelligent Systems, 2008. MFI 2008. IEEE International Conference on],
181
–188
(2008). Google Scholar
Lore, K. G., Sweet, N., Kumar, K., Ahmed, N., and Sarkar, S.,
“Deep value of information estimators for collaborative human-machine information gathering,”
in in [Proceedings of the ACM/IEEE Seventh Int’l Conf. on Cyber-Physical Systems (ICCPS 2016)],
80
–89
(2015). Google Scholar
Krishnamurthy, V. and Djonin, D. V.,
“Structured threshold policies for dynamic sensor scheduling: A partially observed markov decision process approach,”
in IEEE Transactions on Signal Processing,
4938
–4957
(2007). Google Scholar
Porta, J. M., Vlassis, N., Spaan, M. T., and Poupart, P.,
“Point-based value iteration for continuous pomdps,”
Journal of Machine Learning Research, 7 2329
–2367
(2006). Google Scholar
Ahmed, N., Campbell, M., Casbeer, D., Cao, Y., and Kingston, D.,
“Fully Bayesian learning and spatial reasoning with flexible human sensor networks,”
in in [Proceedings of the 2015 Int’l Conf. on Cyberphysical Systems (ICCPS 2015)], accepted, to appear, ACM/IEEE,
(2015). https://doi.org/10.1145/2735960 Google Scholar
Adams, J. A., Humphrey, C. M., Goodrich, M. A., Cooper, J. L., and Morse, B. S.,
“Cognitive Task Analysis for Developing Unmanned Aerial Vehicle Wilderness Search Support,”
Journal of Cognitive Engineering and Decision Making, 3
(1), 1
–26
(2009). https://doi.org/10.1518/155534309X431926 Google Scholar
|